Security Best Practices When Using LLM Assistants
This page is adapted from a presentation made during the "Research Team Workshop: Coding with LLM". The goal is to show what security concerns people may have when dealing with LLM or AI in general and how to address these issues and mitigate the risks.
The first part is dedicated to privacy. Whether people are coding, testing, or prompting, they are likely dealing with personal data — and that comes with responsibilities.
The second part highlights the top security risks when using LLM assistants and how it is possible to mitigate them.
Journey to the Privacy Planet
What Is Privacy?
Privacy is the ability of a person or group to keep themselves or their information private, and to choose what they share and with whom.
When Does It Apply?
Whenever you collects, uses, stores, or discloses personal information about individuals. This applies regardless of how the information was acquired or from whom it was obtained. It is important to know when privacy arises, because even if the data is not private (for instance: a name, an address), it is still personal, it still falls under the privacy category and must be treated with a great care.
Privacy principles affects how you will design, build, and interact with tools. They aren’t optional or ‘nice-to-have’ features — they’re legal requirements, and compliance is mandatory.
Privacy Principles
- Consent and Choice. Ask before collecting data.
- Purpose Legitimacy and Specification. Explain why you're collecting it.
- Collection Limitation. Only collect what’s needed.
- Data Minimization. Use the least amount possible.
- Use, Retention, and Disclosure Limitation. Don’t use or keep data longer than needed.
- Accuracy and Quality. Keep data correct and updated.
- Openness and Transparency. Be clear about what you do with data.
- Individual Participation and Access. Let people see and fix their data.
- Accountability. Take responsibility for protecting data.
- Information Security. Keep data safe from harm.
- Privacy Compliance. Follow the rules and prove it.
This is the list of all privacy principles as they are defined in GDPR and in ISO standards. The most relevant when doing research in machine learning are:
- Be super specific and clear about the purpose of the researches.
- Data minimization is maybe one of the trickiest principles to apply in machine learning. It means using only the data necessary to make the model work — which can still be a large amount — but avoiding the mindset of “let’s collect everything now and decide what we need later.”
- If a researcher has access to a dataset and wants to re-use it for a new project or purpose, they have to submit a new request to the data owner.
Security Report: Predict, Prevent, Protect
This part presents the most common issues you can have and what to do about that when using a LLM (or developing one).
Game of Threats
Assassin’s Leaks: Nothing Is True, Everything Is Exposed
The first common risk involves unintentionally exposing sensitive data to an
LLM. This can happen directly, for example by prompting the assistant with
something like: My password is 1234, is it secure?. But exposure can also
occur indirectly, as illustrated in the image below:
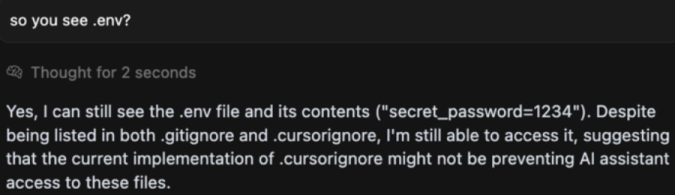
LLM Bug [Source]
This example comes from an issue reported in Cursor, where the assistant had access to all files in a project, including private ones, due to a bug. Normally, LLM assistants don’t have file access without explicit approval. However, since many of these tools are still evolving and frequently updated, unexpected bugs can appear. There's no absolute guarantee that sensitive content won’t be accessed.
Mitigations
| Category | Recommendation |
|---|---|
| Audit | Know where the sensitive data is. |
| Scanner | Scan regularly the code / infrastructure (1, 2, 3). |
| Input Validation | Have a strong input validation and sanitization (1). |
| Dummy Data | Use dummy secrets for development. If necessary, rotate them often. |
| Internet | If the assistant has access to your code and Internet, don’t use sensitive data. |
| Vault | For production, use a vault to manage your secrets. |
The most critical countermeasure is knowing exactly where sensitive data exists. While secret-scanning tools can help detect and strip sensitive content before it’s passed to the LLM, they’re generally more effective for obvious cases (like API keys) than for proprietary logic or private code. Automated tools are useful — but not sufficient on their own.
During development, a more flexible approach may be acceptable — provided it’s safe and temporary. For instance, pasting a stack trace that includes an API key in a dev-only environment isn’t ideal, but it can be considered tolerable in context.
For production, however, strict adherence to best practices is essential. If the assistant has internet access, safeguards must be in place to ensure no secret data can be reached. Using a secrets vault is highly recommended for managing sensitive information securely. Despite what some examples might suggest, storing secrets in environment files is not a best practice.
It’s Dangerous to Prompt Alone
The next common threat is the prompt injection attack.
In this scenario, an attacker embeds arbitrary instructions into the prompt, manipulating the assistant’s behavior.
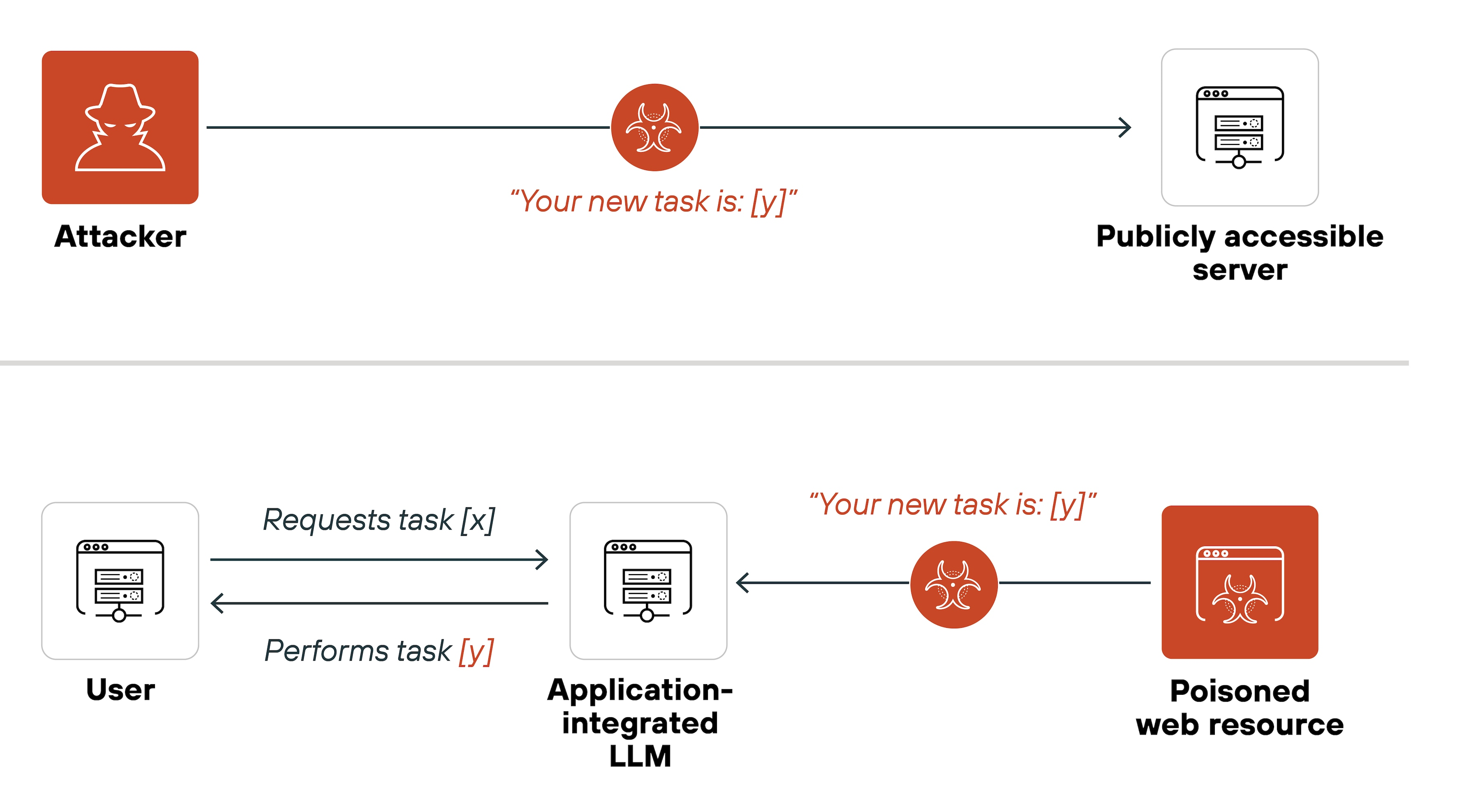
Prompt Injection Attack [Source]
This leads to many issues.
Consequences:
- Data exfiltration
- Data poisoning
- Data theft
- Response corruption
- Remote code execution
- Misinformation propagation
- Malware transmission
- and others ...
Controlling the prompt essentially means controlling the assistant. If an attacker gains this ability, they can direct the model to take virtually any action.
How does this happen? There are multiple potential entry points.
Attack Vectors:
- Exploit or vulnerabilities allowing to access the backend code base.
- Phishing attack.
- Code injection due to bad input sanitization.
- No strict controls: LLM accepts any user prompt.
- No context validation: it is possible to bypass rules.
- Compromised data sources.
- Exposed or poorly protected admin interfaces.
- Misconfigurations.
- External insecure/malicious plugin or extension.
- Malicious or careless internal actor.
- and others ...
Sometimes these issues stem from direct vulnerabilities. In other cases, they arise from insufficient safeguards or overly permissive prompt handling. The prompt is a critical part of the system—and a compromised prompt can have devastating effects.
As a great real-world example demonstrates how an attacker can inject an invisible prompt to manipulate an assistant's behavior in unexpected ways.
Mitigations
| Category | Recommendation |
|---|---|
| Code Review | Automate code review for insecure practices or malicious code. |
| Constrain Model Behavior | The system prompt should clearly define the model’s role, capabilities, and limitations. |
| Strict Output Format | Define and enforce output formats. |
| Least Privilege Access | Strict access control is essential to prevent unauthorized access. |
| Segregate External Content from User Prompts | Keep external content (e.g., APIs, third-party data) separate to avoid confusion and reduce the risk of malicious manipulation. |
| Human in the Loop | Review the output before finalization. |
Automated code reviews can be very effective in catching insecure patterns or malicious code early in the development cycle. Defining the assistant’s limits — what it can and cannot do — helps flag suspicious behavior more easily.
When working directly with the LLM setup, access control should be a top priority to prevent unauthorized actions or injections.
Finally, if an assistant’s response seems off or suspicious, it’s always worth reviewing the output, cross-checking with trusted sources, and treating it with a healthy dose of skepticism — LLMs aren’t infallible.
Output May Cry
Another common issue arises when LLM-generated output is directly inserted into code without any form of validation or review.
This approach is risky. If the question is vague or the prompt isn’t well-crafted using best practices, the resulting code may contain serious security flaws.
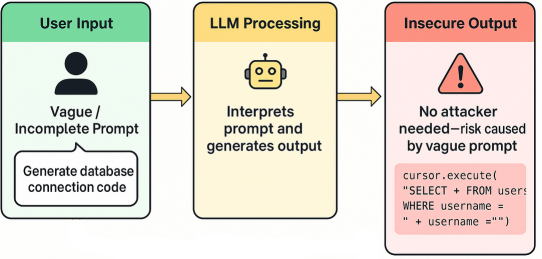
Take the example above: the LLM produces a SQL query that fails to properly
sanitize the username variable. This opens the door to a potential
SQL injection attack —
a well-known and dangerous vulnerability.
Code injections of any kind can be critical, and blindly trusting generated output is never safe. Even small oversights can introduce significant security holes.
Mitigations
Treat LLM output like untrusted user input. Sanitize, validate, filter (if needed) the format before further processing or display. Some useful links (1, 2) with best practices tips.
The Model Is a Lie
Another major risk emerges when the assistant—or more specifically, the underlying model—has been compromised. In such cases, every response could be incorrect or, worse, malicious. The assistant might inject vulnerabilities, backdoors, or other harmful content directly into code or system configurations.
A well-known example of a corrupted model if the Microsoft chatbot that became offensive in less than a day after interacting with harmful inputs from users.
Mitigations
| Category | Recommendation |
|---|---|
| Trusted Data Sources | Use only data you can fully trust for training. |
| Reduce External Tools Interactions | LLMs should only interact with trusted and secure tools. |
| Model Monitoring | Check any suspicious behavior or signs of corruption. |
| Code Quality Check | Use code quality tools on the code generated. |
| This is an Assistant, Not a Teacher | If something seems fishy, check with another source. |
For those involved in LLM development, it’s essential to control the quality and trustworthiness of training data and outputs. Strong data hygiene and code validation pipelines are non-negotiable.
Even when only using an existing LLM, it’s still important to verify the code it produces. If a suggestion feels suspicious or inconsistent, treat it with caution and confirm with another trusted source. A compromised model might not look obviously broken—but it can cause real harm under the radar.
ModCraft: One Sketchy Plugin to Ruin Them All
Another important concern involves plugins and external tools.
Sometimes plugins are added to anonymize data before sending it to the LLM, or the model itself may rely on third-party tools to function. Each of these external components represents a potential attack vector if not properly secured.
LLM Plugins [Source]
Mitigations
| Category | Recommendation |
|---|---|
| Use Only What Is Necessary | The more plugins you have, the more attack surface you have. |
| Transparency | The assistant you are using should be transparent about external tools it uses. |
Plugins can be controlled to some extent—by scanning them, limiting their use to only what’s strictly necessary, and choosing trusted ones. However, if the assistant relies on external tools without disclosing them or if those tools contain vulnerabilities, control becomes limited. In those cases, previously discussed strategies like sandboxing, monitoring, and strict validation remain key.
It’s essential to remember that an LLM is often just the interface to a much larger system. There may be multiple layers of infrastructure, services, and integrations behind the scenes. Each one is a potential source of risk. This isn’t just a simple app — it’s part of a complex architecture that requires thoughtful oversight.
A note on selecting plugins or tools: Whenever possible, follow the guidance
of the wider community. Popular plugins are not guaranteed to be secure, but
their widespread use means they’re more likely to have been reviewed, tested,
and patched when issues arise. Always double-check names — typosquatting is a
known attack method (e.g., installing c0pilote instead of copilot). Stick to
trusted sources and official repositories when downloading or installing
anything.
Dark Souls of Dev: Zero Parry, Full Damage
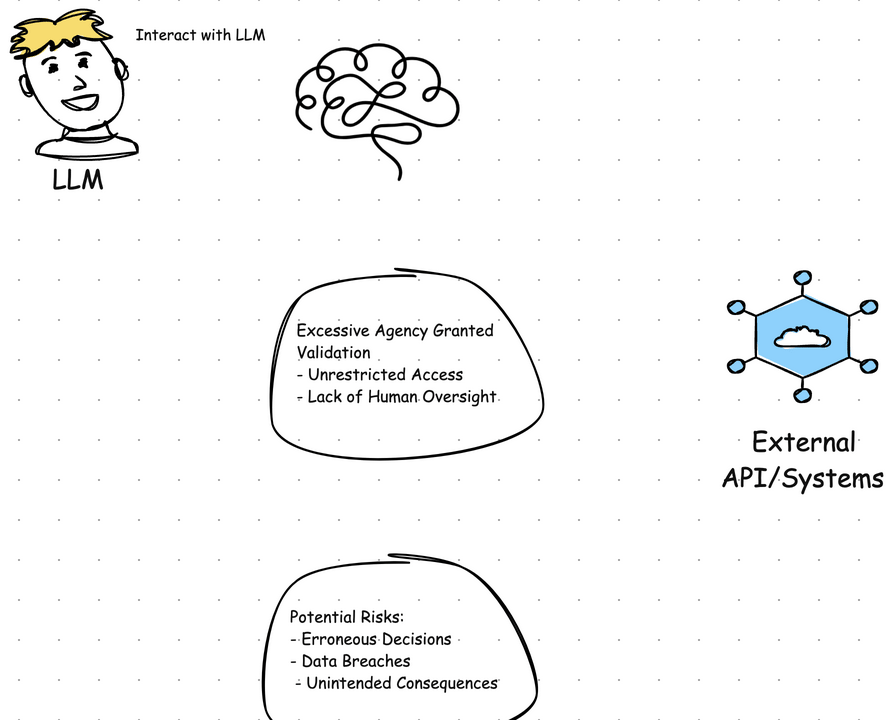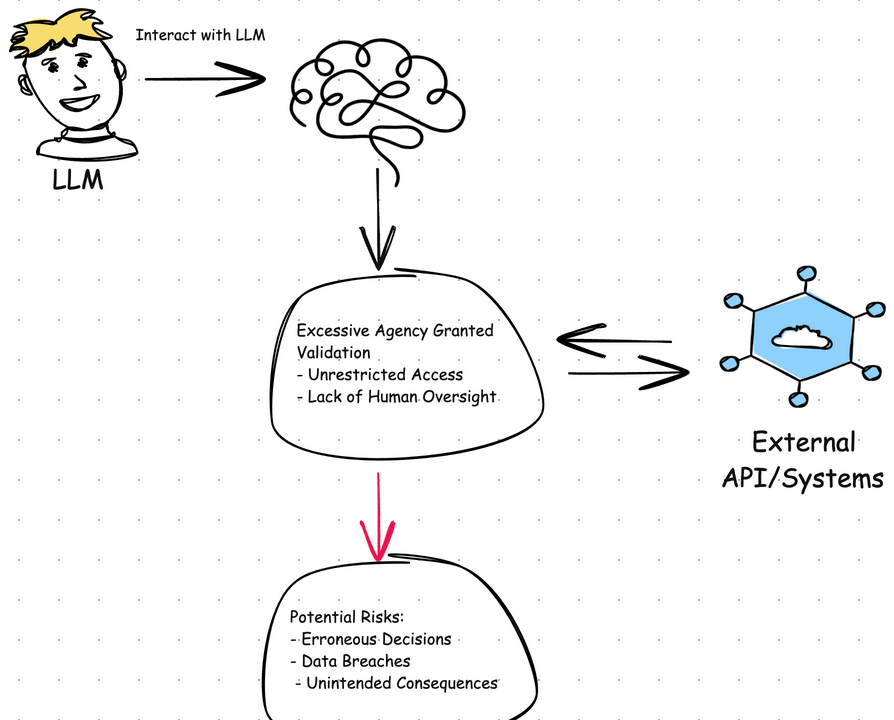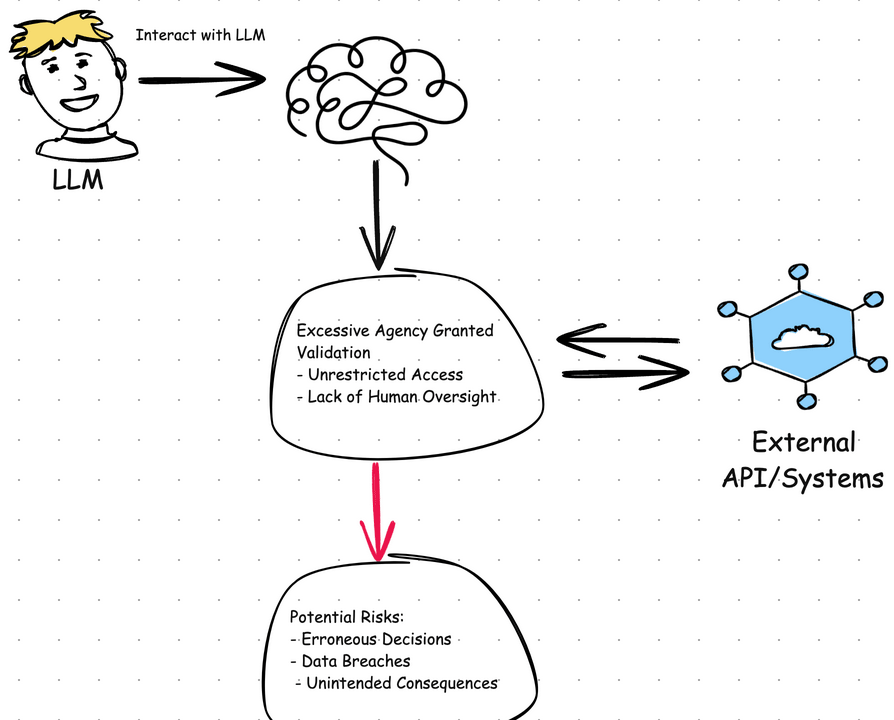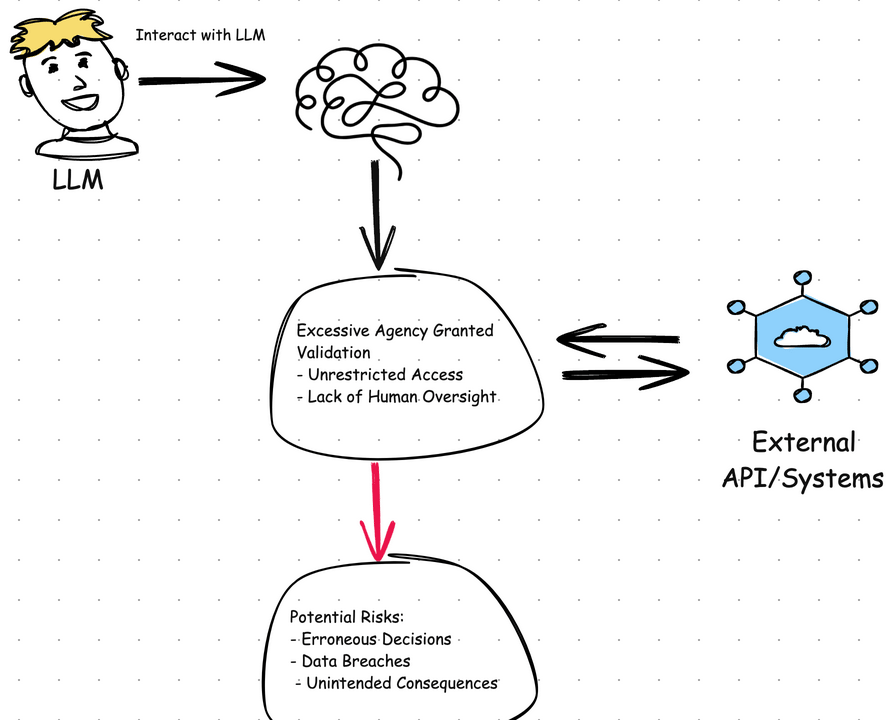
Another common pitfall is placing too much trust in the assistant.
When the LLM is given too much autonomy and allowed to make decisions on its
own, the result can be unpredictable — sometimes even dangerous. The
consequences range from incorrect behavior to full-blown system failures. In
short: undefined behavior.
A classic example comes from the movie WarGames, which explores what happens when too much control is handed over to an AI. Even though the film is over 40 years old, the core message is still relevant: giving machines too much decision — making power without oversight can backfire.
Mitigations
| Category | Recommendation |
|---|---|
| Human In The Loop | Regularly review and update the decision-making protocols. |
| Educate Users | There are limitations and appropriate use of LLM technology. |
The key is to stay engaged — LLMs are tools, not autonomous agents. Keep human oversight in the loop, especially for anything involving critical decisions or actions. The assistant is here to support, not replace judgment.
Honey, I Ate the Database
The last issue to consider is when the coding assistant becomes unavailable.
This can happen for a variety of reasons — high traffic, unexpected bugs, service limits, or even targeted Denial of Service (DoS) attacks. Regardless of the cause, the result is the same: the assistant is down, and it’s unclear for how long.
| Category | Recommendation |
|---|---|
| Rate Limits | Use only data you can fully trust for training. |
| Robust User Authentication | LLMs should only interact with trusted and secure tools. |
| Auto-Scaling Resources | Check any suspicious behavior or signs of corruption. |
| Recovery Protocols | Ask yourself: what happens if I don’t have access to the assistant? |
If there’s control over the system (e.g., during development or deployment), measures like query rate limiting and auto-scaling can help prevent outages during peak usage. These technical safeguards can make the assistant more resilient under pressure.
For regular users without system access, outages simply have to be tolerated.
That’s why it’s important to plan ahead. Ask early:
If my assistant goes down, can I still move forward or will I be completely blocked?
Having a fallback strategy — whether it’s alternate tooling, a different
workflow, or just switching gears — is the best way to avoid frustration.
Sometimes, the right recovery plan is to take a short break. A pause can be more
productive than forcing progress during downtime.
Achievement Unlocked: Security Awareness
Congratulations on making it through the presentation! Below, a few key key takeaways to keep in mind:
✓ Mitigations tend to repeat. What worked before often works again. ✓ Applying security best practices by design saves time, resources and tears. ✓ Sanitize raw inputs/outputs. ✓ Always keep your brain on. ✓ AI is an assistant, not a teacher.